 |
|
|
|
|
|
What's
New in TextMaster Data Editor v.2.5
 |
(Your current version of TextMaster Data Editor can be found: Help >> About
and last update date Help >> User's Guide front page "Last Update:")
The following is the list of the bug fixes in 2.5 release
March 2nd service release, 2009:
“TextMaster Query” screen –“Query” text box, after resize
didn’t have a proper size. It was exceeding visible area and editing of the
long queries was difficult.
“TextMaster Query” screen – query expansion screen was
reporting an error if connection template was embedded into command even thou
query was correct.
“Associations” screen – “Save” button was reporting an
error (“Extension must be 3 characters long ….”) for global associations in some
cases when extension was correct and was preventing modifications of global and
directory associations.
The following is the list of the major changes (fixed bugs) in 2.5 release
as of February 18th, 2009:
Aggregates - SELECT statement can have count (count
all records which meet where clause condition(s) (if any), min , max and sum
aggregate functions as parameters.
Global Variables added for batch processing - string, int,
long, decimal, char and DateTime can be declared, assigned and used in TMQL
statments (command parameters and "where" clause). variable definitions support
aggregates (count, min, max and sum) as well.
TimeDifference function which retrieves years, months,
days, hours, minutes and seconds elapsed between two DateTime variables as
integer added.
Error - TMQL command which terminates batch with an error
added. All changes to that point will be reversed if "Transactional" global
parameter is set. This command is particulary useful for Query Batch data
validations.
Report - TMQL command which will add line to the "Report"
section of the "Query Batch" is available. This command can provide "warnings"
as a part of the batch processing validation process or summary report of the
processing results.
More details about any of the features can be found in User's
Guide (from Windows Start >> TextMaster >> Data Editor User's Guide or from
TextMaster Data Editor Help >> User's Guide)
The following is the list of the major changes (fixed bugs) in 2.5 release
as of January 11th, 2009:
Editing - After file check number of lines displayed can be changed,
displayed lines can be edited and save in another file, edited values can be
undone or redone and parts of the lines can be marked with different colours. TextMaster Query functionality is significantly improved by adding snippets for
accelerated data entries.
Encoding - File encoding can be selected for the file checked or
exported, all TMQL (Select, Update, TMDeDup …) will use specified file encoding.
Encoding is added to the connection setup wizard. Split and Join utilities have
encoding added as additional parameters.
Vertical Join - TMVJoin command converts all lines or set of lines
(segments) from text file into single line or multiple lines where every line
becomes field in destination file. Fields in destination file are delimited
using specified delimiter. If segments from the source file are converted into
lines in destination file then marker (segment indicator) can be at the
beginning or at the end of the segment. Query Batch – one or more queries can be saved in a text file
with “.tmb” extension. When executed queries are executed in sequential order
and if any of the queries fails all changes to the files are rolled back. Backup
and restore functionality can be disabled if it’s not required. TMFile, Windows
Explorer type of file processing capabilities, is added to enhance TMQL
capabilities and add flexibility to the Query Batch functionality.
Associations - connection templates are stored in repository. By
storing templates (global file descriptions) into repository associations
between file extension and file can be defined globally (every file in any
directory will have automatically associated with file description) and / or
files with specified extension can be associated with a template for single
directory (including subdirectories). This feature eliminates a need for
defining connection for every file.
Furthermore, by using Windows file extension association any file extension can
be associated with template and by double clicking file in Windows File Explorer
TextMaster will be opened and checked. Query screen will open as well and all
lines will be displayed.
In addition to this, there are five system templates, which do not appear in
template repository but can be referenced in queries:
- _Template_1_FIX
- _Template_1_TAB
- _Template_1_Comma
- _Template_1_SemiColumn
- _Template_1_Pipe
Line content in “where” clauses can be referenced as FIELD_0 or Line.
Pseudo system templates (templates which are created on the fly) can be
used as well. There are four delimited types available:
- TAB
- Comma
- SemiColumn
- Pipe
For example,
select * from C:\TMSampleData\SampleData.csv(_Template_11_COMMA)
will create connection (comma delimited with 11 fields) on the fly and will
ignore connection “C:\TMSampleData\SampleData.tmc” (if exists).
NOTE: Field can be referred as FIELD0, FIELD1 … FIELD10.
System templates and repository templates can be referenced in a query along
with the file name (late biding) and on that way necessity for connection to
be created before file is used. Connection must be created only if file
encoding must be specified (not default) and fields must be named. It comes
particularly in handy when queries are used and file name is created on the fly
(see more details in the User's Guide under 'Query Batch' section).
Global Settings – are added to improve flexibly of the TextMaster Data
Editor and to allow users to customize TextMaster Data Editor to better meet
specific needs (be default data editor, data reader for specific file types
…)
|
The following is the list of the major changes (fixed bugs) in 2.2 release
as of March 19th, 2008:
-
Split File utility added– will split file into specified number of files
or into calculated number of files based on number of lines in the component
files
-
Join File Utility - will join all component files into the original
file. After any component is selected, the result file name, as well as the
destination folder, will be populated with original file name and folder
path of the components respectively.
-
TMKeep bug fix – query
tmkeep "<tr>"+Name+"</tr>" as Name,"<tr>"+Phone+"</tr>" as Phone from C:\TMSampleData\SampleData.tmc
was keeping proper number of columns (Name and Phone) but content of the
fields was "<tr>Name</tr>" and "<tr>Phone</tr>" respectively. Fields in
between two literals were treated as literals and not as a fields.
The following is the list of the major changes (fixed bugs) in the
February 19th, 2008 release:
- TMDeDup statement added – which removes duplicated
lines from the file using one or more fields as criteria. String functions
can be used to upper or lower case fields, limit criteria only to the part
of the field, trim field etc. “Where” clause can be used to eliminate lines
from the file and “top” and “offset” feature can be used on the same way.
Examples:
- Query TMDeDup Province from C:\TMSampleData\SampleData.tmc
Produces the following result
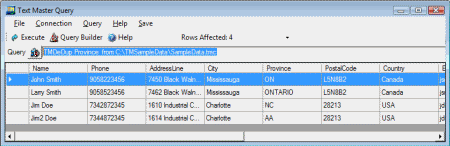
(click on the image to enlarge)
File before de duplication was like this
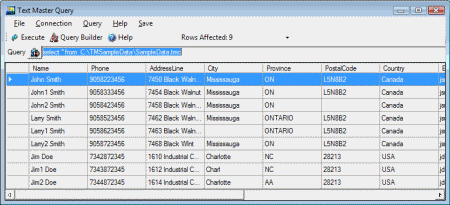
(click on the image to enlarge)
- Query TMDeDup City,Country from C:\TMSampleData\SampleData.tmc
As result C:\TMSampleData\SampleData.csv will have four records (two for
Canada and two for USA).
- Query TMDeDup Phone.Substring(0,3) from C:\TMSampleData\SampleData.tmc
As result C:\TMSampleData\SampleData.csv will have only two records because
first three digits of every Phone are “905” or “734”
- TMHSplit statement added – which splits file into
several files using one or more fields as criteria. String functions can be
used to upper or lower case fields, limit criteria only to the part of the
field, trim field etc. “Where” clause can be used to eliminate lines from
any of component files and “top” and “offset” feature can be used on the
same way. If source file has header as the first line every component file
will have the same header.
Component files have the same name as source file extended with “_” and <field_value>[“_”+<field_value>….].
extension of the component files is the same as extension of the original
file.
Examples:
- Query TMHSplit Province from C:\TMSampleData\SampleData.tmc
Will divide content of the file c:\TMSampleData\SampleData.csv into
C:\TMSampleData\SampleData_ONTARIO.csv
C:\TMSampleData\SampleData_ON.csv
C:\TMSampleData\SampleData_NC.csv
C:\TMSampleData\SampleData_AA.csv
- Query TMHSplit City,Country from C:\TMSampleData\SampleData.tmc
Will divide content of the file c:\TMSampleData\SampleData.csv into
C:\TMSampleData\SampleData__Canada.tmc
C:\TMSampleData\SampleData_Mississauga_Canada.tmc
C:\TMSampleData\SampleData_Charl_USA.tmc
C:\TMSampleData\SampleData_Charlotte_USA.tmc
- Query TMHSplit Phone.Substring(0,3) from
C:\TMSampleData\SampleData.tmc
Will divide content of the file c:\TMSampleData\SampleData.csv into
C:\TMSampleData\SampleData_734.tmc
C:\TMSampleData\SampleData_905.tmc
- TMKeep statement added – which removes columns by
specifying individual field(s) and / or segments of the field(s) to remain
in the file. Fields can be renamed, new fields added as constants and/or
combination of the existing fields. For fix file type field length of one or
more fields can be changed with TMKeep command. New description (connection)
is created automatically. Order of the columns can be changed with single
command. By using “where” clause rows with specific values can be excluded
at the same time. “Top” and “Offset” options can be used to limit number of
rows in the modified fields to the selected segment of the file.
Examples:
1 - Query TMKeep Name,Phone,Email from
C:\TMSampleData\SampleData.tmc
As result C:\TMSampleData\SampleData.csv will have only three columns Name,
Phone and Email.
2 - Query TMKEEP
Date,Amount,Company,Email,Country,PostalCode,Province,City,AddressLine,Phone,Name
FROM C:\TMSampleData\SampleData.tmc
As result C:\TMSampleData\SampleData.csv will have columns in reverse order.
NOTE: For text file with fix type all fields will be properly mapped. To
check it, execute
3 - Query TMKEEP Date,Amount,Company,EMail,Country,Postal,Province,City,AddressLine,Phone,Name
FROM C:\TMSampleData\SampleDataFix.tmc
and open connection C:\TMSampleData\SampleDataFix.tmc
4 - Query TMKeep Name,Phone.Substring(0,3) as
AreaCode,Phone.Substring(3) as Exchange,
Email from C:\TMSampleData\SampleData.tmc
As result C:\TMSampleData\SampleData.csv will have four columns and phone
number will be divided into two fields (AreaCode and Exchange).
5 - Query TMKEEP top(5) offset(2) Name,Phone,Company from
C:\TMSampleData\SampleData.tmc
As result, C:\TMSampleData\SampleData.tmc will have only three columns
Name,Phone and Company and five rows (including header).
6 - Query TMKEEP Name,AddressLine as
AddressLine1,City.Trim()+","+PostalCode.Trim()+","+Country.Trim() as
AddressLine2
from C:\TMSampleData\SampleData.tmc
As result, file C:\TMSampleData\SampleData.csv will have three columns
(Name, AddressLine1 and AddressLine2). AddressLine2 is concatenated from
City, PostalCode and Country.
- For quick start, wizards for newly added statements are
available. Wizards for all TMQL statements can be found under TextMaster >>
TextMaster Query >> Query Builder.
The following is the list of the major changes (fixed
bugs)TextMaster v2.0.2954 as of February 2, 2008:
- Problem: For delimited files delimiters outside of the 0 – 127
(decimal) range
(i.e. if delimiter was character “¤”) were not saved
properly.
Solution: Connection encoding was
changed from UTF-8 to UTF-16. User interface is not affected.
- Problem: If SPACE (48 – decimal) was used as delimiter, field
parsing was not working properly
and delimiter presentation was not user friendly.
Solution: New option for delimiters
(“Space”) was added to the connection wizard screen and
code is changed to accommodate “Space” as any other delimiter.
- Problem: If font size for the desktop was large than connection
wizard would not show all fields.
Solution: Connection wizard screen was
made resizable.
- Problem: If rows were ending with double quotes file check was
reporting error message and was shutting down TextMaster.
Solution: Problem is fixed.
|
- Skip Invalid Record
- Field name(s) suppression
- Skip first line
- Automated naming
- Load test data
- Save query results
- Auto File type
- File name with multiple
dots
- No special treatment
for quotes
- Optimize performance
- Save current view
- Recently executed queries
|
|
 Skip Invalid Record
Skip Invalid Record
Requirement:
Process lines with the number of fields for delimited files, or the line
length for fix length files, different than defined in the connection (file
description).
Implementation:
Prior to this change, lines with invalid length were skipped and reported as
invalid. The new check box “Skip Invalid Line(s)” determines if invalid lines
should be processed or not.
Default value is unchecked (do not skip invalid lines).
|
Note:
After the new version of TextMaster is installed, all existing connections will
have this behavior. To restore the original behavior open connection, check
“Skip Invalid Line(s)” check box and save connection. |
|

|
|
 top top
|
Field name(s) suppression
Requirement:
Upon various circumstances, queries will report an error because field names
contained spaces and/or special characters (@,!,&,? …). Spaces and special
characters should be removed from the field names.
Implementation:
During connection save process, every field is checked for spaces and
special characters ((, ), +, -, /, *, [ , ], {, }, \, =, &, ;, |, !,
>,<,.,",',@,#,$,%,^,_,~,: as well as commas (,)). If any are found, a
warning will pop up

|
|
Note:
The cancel button will terminate the save operation and no fields will be
changed.
|
|
top
|
Skip first line
Requirement:
If the connection has "Skip First Line (Names)" checked, select statements
should skip the first line automatically and eliminate need for the
Offset(2) clause, in the select statement, to enforce it.

Implementation:
For connections with “Skip First Line (Names)” checked, if offset clause
does not exist or the value is less than 2 , then the offset value will be
set to 2 automatically and the first (header) line will be skipped.
|
|
top
|
Automated naming
Requirement:
Connection field names are automatically generated as FIELD0,FIELD1 … when
header does not exist. Queries with a “where” clause were reporting an error if
field names had “FIELD” as a part of it.
Implementation:
In the previous release, by using @@FIELDxx (xx - is a zero based field
index) instead of a field name in the “where” clause, field could have been
referenced. Instead of using “@@FIELD” as prefix, in this new release , “FIELD_”
can be used as a prefix. For example, instead of using field name “Name” , which
is the first field in “SampleData.tmc” connection, in the query,
select * from C:\TMSampleData\SampleData.tmc where FIELD_0.Contains("J")
“FIELD_0” can be used.
|
|
top
|
Load test data
Requirement (bug fix):
If “C:\TMSampleData\” had other files besides the sample data supplied as
part of the TextMaster release, then reloading of the sample data couldn’t
complete.
|
|
top
|
Save query results
Requirement :
After “select” query execution “Save>>Query Results” should save only fields
listed in the query, using the names used in the query (including those
modified with the “as” statement).
Implementation:
Before the change, “Save>>Query Results” was creating new connections with
all fields from the connection used in the query and inserting only lines
which would conform to the “where” clause requirements. New implementation,
inserts only listed fields under the same or modified name (modified with
“as” clause) . For fixed fields, length is transferred from the connection
in the query. If the field does not exist, for fix fields, a prompt will pop
up providing the option of supplying the length of the field. “Start” and
“End” values for every field are recalculated automatically.
For example, query
select Name,Phone.Substring(0,3) as AreaCode,Phone.Substring(3) as
Exchange,AddressLine from C:\TMSampleData\SampleData.tmc where
FIELD_0.Contains("J") has the following result:

“Save >> Query Result” will create the following connection automatically

Query
select * from C:\TMSampleData\SampleDataSaveQueryResult.tmc
will produce the following result:

|
|
top
|
Auto file type
Requirement (bug fix):
Analyze up to 10000 lines and find the max percentage of those which have
the same length in characters, or the same number of fields using comma,
semicolumn, pipe or TAB as delimiters. If any group meets the minimum
requirement (75%) use the one with max percentage as the file type
indicator.
Note:
Before this fix as soon as the first group met minimum requirements, the
process would have stopped.
|
|
top
|
File name with multiple dots
Requirement (bug fix):
If file has multiple dots in the name, for creation of the “.tmc” equivalent
use last dot and replace rest of the name (presumable extension) with “tmc”.
|
|
top
|
No special treatment for quotes
Requirement:
For delimited files, the option to treat quotes as any other character is
required.
Implementation:

|
New drop down option (“Disregard”) is added to the description of the delimited
files.
Option “None” and “Disrigard” have a lot of similarities. Both do not expect
every field to be enclosed in quotes (single or double). Unlike the “Disrigard”
option, “None” will look for part of the line which starts with the delimiter
immediately followed by double quote and everything to the next double quote and
delimiter (or end of the file) would be considered as one field. MS Excel is
using the same approach to allow commas to be part of the data field (in “.csv”
file) and not delimiter.
|
|
top
|
Optimize performance
Requirement:
Accelerate file check, export and query performance.
Implementation:
Code optimization increased performance in targeted segments. In addition
there are two new fields available as result of the select statement
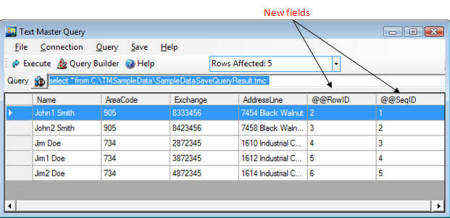
(click on the image to enlarge)
@@SeqID – line number in the current view
@@RowID – line number in the file
Note:
In the example above, @@RowID starts with 2 because the file has a header
and it’s not part of the current view (is skipped).
|
|
top
|
Save current view
Requirement:
Displayed results can be edited and sorted. Saving changed values in
selected order is required.
Implementation:
New function “Save >> Current View” and “Save>>Append Current View” have
been added.

A new connection is created, on the fly, using the connection specified
in the query.
For delimited files, fields named as view headers would be automatically
created.
For fixed fields, field names same as view header titles are created and if
they exist in the connection which was used in “select” statement length is
transferred as well. If field does not exist, a prompt will pop up providing
the option of supplying the length of the field. “Start” and “End” values
for every field are recalculated automatically.
“Save>>Current View” will overwrite file to which selected connection is
pointing to, if exists, and “Save>>Append Current View” will append data, if
file exists.
|
|
top
|
Recently executed queries
Requirement:
Provide a way for quick retrieval of the recently executed queries.
Implementation:
List of the last 10 executed queries can be found under the File menu.
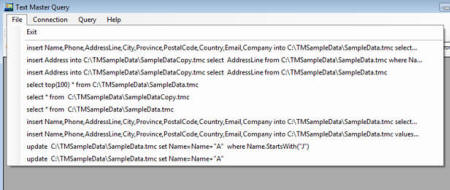
(click on the image to enlarge)
|
|
top
|
|
|
|







